Quick answer
For most teams, the right choice is not purely software or purely service. The right choice depends on team capacity, update frequency, data complexity, and how quickly you need predictable execution.
Software can improve control and transparency, while services can reduce operational load. The key is matching model type to workflow maturity, not buying based on price alone.
If you are evaluating options, treat local listing management software as a process fit decision, not just a feature checklist.
sbb-itb-8e44301
Problem framing
Teams often frame this as a binary decision: "tool or agency." In practice, the decision is about operating model design. If your current workflow is unstable, both choices can underperform for different reasons.
Common decision errors:
- buying software without internal ownership capacity,
- hiring a service without clear quality controls,
- expecting immediate outcomes before process stabilization,
- evaluating by monthly cost while ignoring correction overhead,
- scaling before baseline consistency is achieved.
These errors create the same outcome: recurring cleanup work and low confidence in reporting.
Software vs service capability map
| Dimension | Software-led model | Service-led model | Hybrid model |
|---|---|---|---|
| Control over updates | High | Medium | High on standards, shared on execution |
| Internal workload | Medium to high | Low to medium | Medium |
| Speed to launch | Medium | Medium to high | Medium |
| Consistency risk | Depends on team discipline | Depends on provider process | Lower when governance is clear |
| Scalability | High if process is mature | High if service quality is stable | High with good handoff design |
No model is universally best. Fit is contextual.
Team-fit matrix (how to choose)
| Team reality | Better starting model | Why |
|---|---|---|
| Small team, low ops bandwidth | Service-led or hybrid | Faster execution with less internal overhead |
| Medium team, strong operations owner | Software-led or hybrid | Can maintain controls and iterate quickly |
| Multi-location with frequent updates | Hybrid | Balances control and throughput |
| High compliance sensitivity | Software-led with strict governance | Better control over approvals and logs |
A bad fit usually shows up as either internal overload (software mismatch) or weak transparency (service mismatch).
Cost interpretation beyond subscription price
| Cost layer | Software-led risk | Service-led risk | How to evaluate |
|---|---|---|---|
| Direct spend | Tool fees may look low initially | Service fee may look higher upfront | Compare total delivery scope, not line-item price |
| Operational effort | Internal setup/maintenance burden | Vendor management overhead | Estimate owner-hours per week |
| Correction cost | Errors from poor internal process | Errors from weak provider QA | Track correction cycle time and recurrence |
| Decision cost | Data is available but not acted on | Reports may be activity-heavy | Require action-oriented reporting |
Teams should measure total operating cost, not just invoice cost.
Decision framework: choose software, service, or hybrid
Use this sequence:
- Assess internal ownership readiness.
- Assess required execution speed.
- Assess quality-control maturity.
- Assess reporting needs for decision cadence.
- Choose model with lowest combined execution + correction risk.
If readiness is low but urgency is high, hybrid is often the most stable transition path.
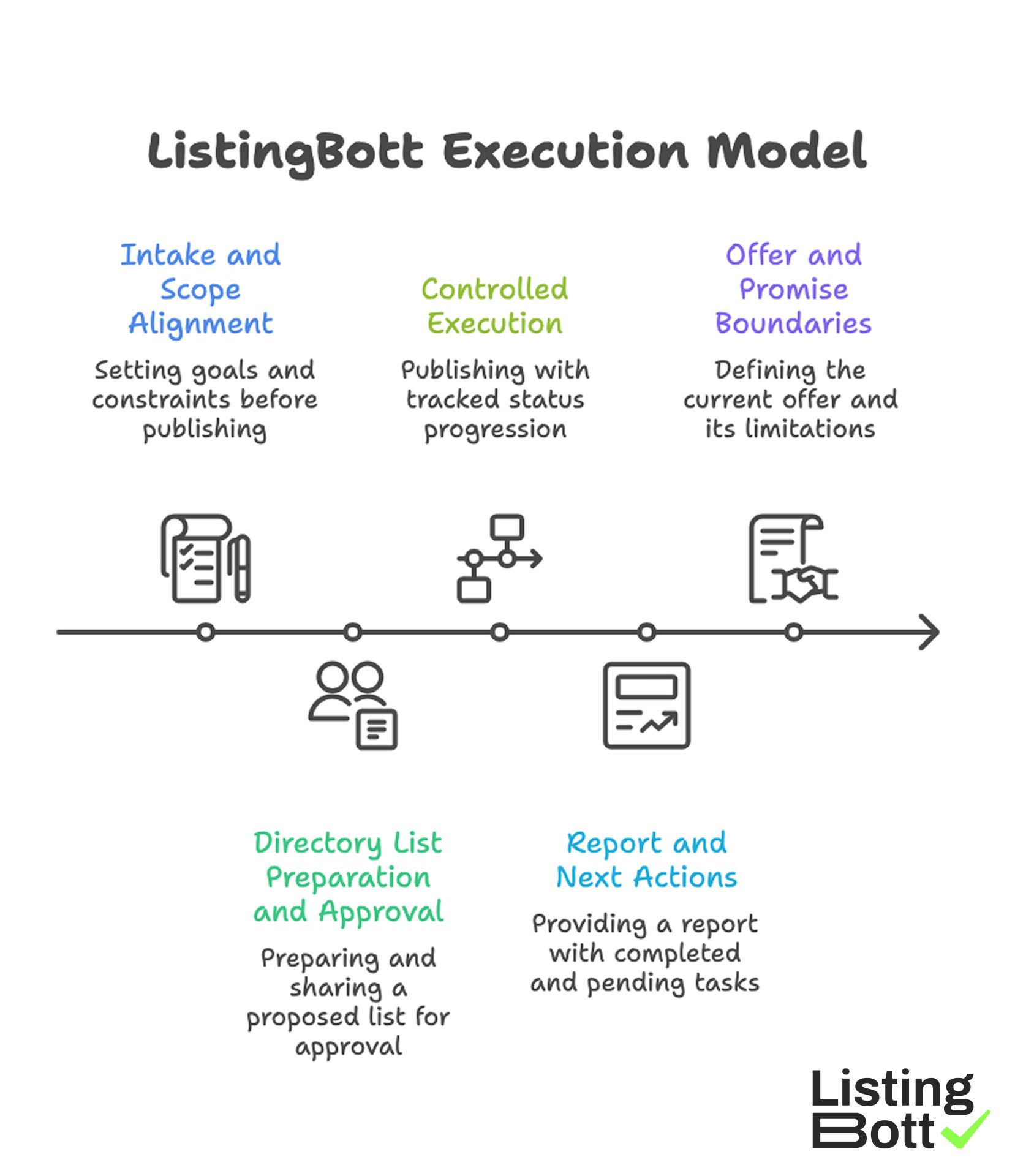
How ListingBott works
ListingBott follows a structured execution model: client-form intake, directory-list preparation and approval, publishing, and report handoff. This model is designed for teams that need process clarity and status visibility.
1) Intake and scope alignment
Execution starts with complete intake so goals and constraints are set before publishing.
2) Directory list preparation and approval
A proposed list is prepared and shared for approval before full publishing begins.
3) Controlled execution
Publishing runs with tracked status progression, which improves consistency and troubleshooting.
4) Report and next actions
Each cycle ends with report-ready output that includes what was done, what is pending, and what to do next.
5) Offer and promise boundaries
Current offer framing includes one-time payment model, publication to 100+ directories (per current website language), no hidden extra fees (per current FAQ language), and refund possibility when process has not started.
ListingBott does not promise guaranteed ranking positions, guaranteed traffic by a specific date, guaranteed indexing speed, or outcomes controlled by third-party platforms.
For DR-goal projects, DR growth to 15 is only in the qualified setup: starting DR below 15, explicit domain growth goal, and approved directory list.
Teams implementing this model can map it to their broader local submission workflow for cleaner execution handoffs.
ListingBott Execution Model
Proof/results
To compare software vs service fairly, teams need a common measurement framework. Otherwise each option looks good on different, non-comparable metrics.
90-day comparison scorecard
| KPI category | Example metrics | Why it matters | Review cadence |
|---|---|---|---|
| Process readiness | owner assignment, checklist completion rate | Predicts execution stability | Weekly during rollout |
| Quality control | inconsistency rate, correction turnaround | Predicts maintenance burden | Weekly |
| Delivery reliability | wave completion vs plan, pending issue age | Predicts operational throughput | Weekly |
| Decision quality | report action adoption rate | Predicts optimization velocity | Monthly |
| Outcome support | referral trend, assisted commercial actions | Predicts business contribution | Monthly |
This scorecard allows apples-to-apples evaluation across model types.
Pilot design for fair model testing
If possible, run a controlled pilot:
- same business scope,
- same baseline period,
- same KPI definitions,
- same review cadence.
Without a controlled frame, model comparisons become opinion-based.
Break-even thinking for model choice
| Scenario | Signals that software-led is better | Signals that service-led is better |
|---|---|---|
| Internal team bandwidth | Team has reliable weekly capacity | Team bandwidth is inconsistent |
| Governance maturity | Strong owner and change policy exist | Governance is still developing |
| Speed requirement | Can onboard in planned phases | Need immediate execution support |
| Update volatility | Frequent controlled updates needed | Updates are moderate but operationally heavy |
Most teams evolve over time. A model that fits today may need adjustment after scale.
Risk controls by model type
| Risk | Software-led mitigation | Service-led mitigation |
|---|---|---|
| Underused system | Enforce weekly operating cadence | N/A |
| Vendor opacity | N/A | Require stage-level visibility and status transparency |
| Data drift | Canonical field governance + QA checks | Approval gates + report checks |
| Slow issue closure | SLA dashboards + owner escalation | Service-level SLA and escalation terms |
| False performance confidence | KPI hierarchy and trend windows | Action-focused reporting and periodic audits |
Risk control is what makes model selection durable.
Interpreting outcomes with realistic expectations
Neither software nor service should be sold as instant ranking guarantees. Reliable evaluation should focus on workflow stability first, then directional outcome support over repeated cycles.
That approach reduces churn caused by mismatched short-term expectations.
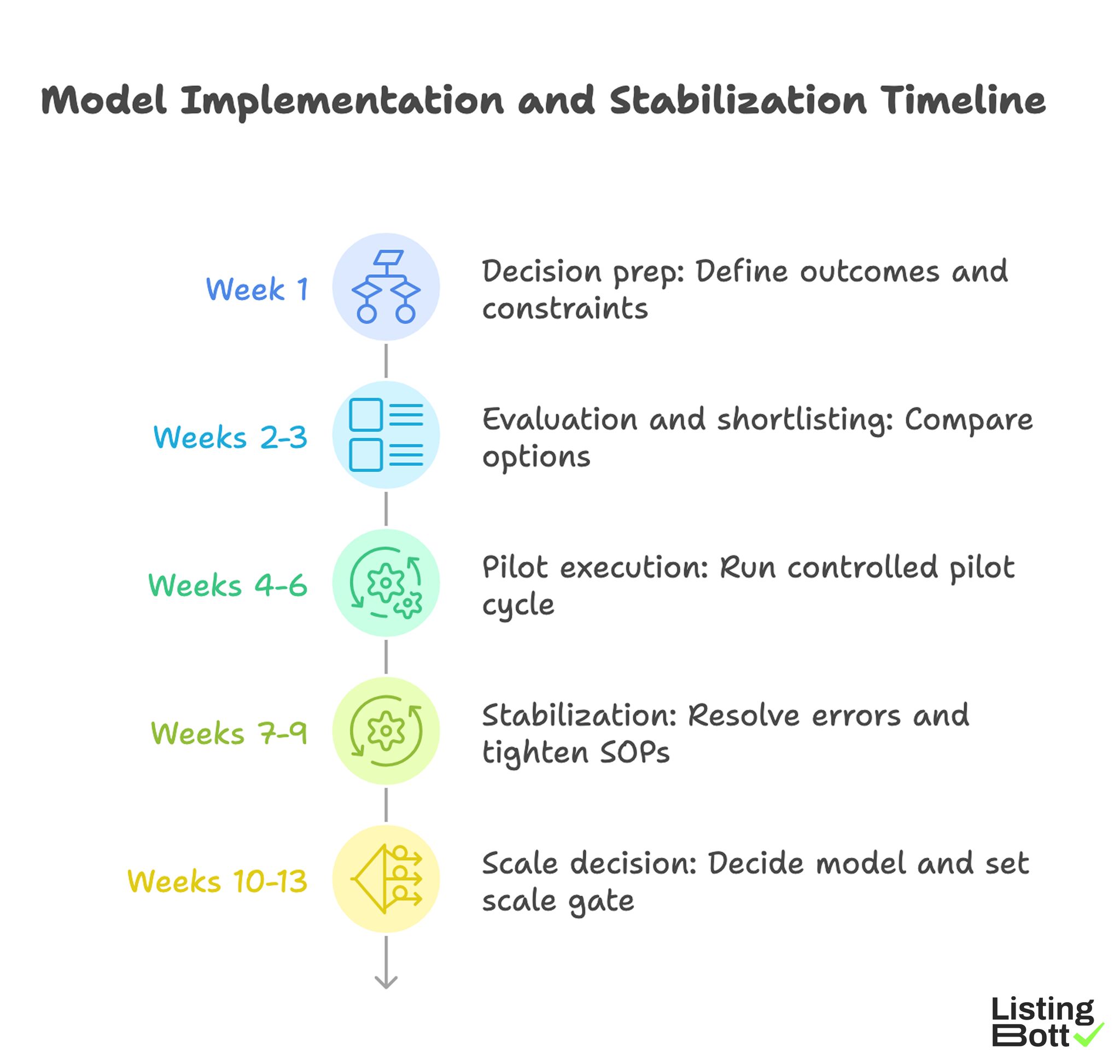
Implementation checklist
Use this checklist to choose and deploy the right model with minimal rework.
Phase 1: Decision prep (week 1)
- Define required outcomes and constraints.
- Document current workflow maturity and team capacity.
- Establish KPI definitions before tool/vendor evaluation.
- Set acceptable correction SLA thresholds.
- Assign decision owner and technical owner.
Phase 2: Evaluation and shortlisting (weeks 2-3)
- Score software, service, and hybrid options on team fit.
- Request process visibility details, not just feature lists.
- Validate how each option handles corrections and escalation.
- Compare total operating cost assumptions.
- Select pilot scope and timeline.
Phase 3: Pilot execution (weeks 4-6)
- Run one controlled pilot cycle.
- Track readiness, quality, and reliability KPIs weekly.
- Log recurring blockers and owner actions.
- Measure decision latency after each report.
- Hold a midpoint correction review.
Phase 4: Stabilization (weeks 7-9)
- Resolve recurring errors by root cause.
- Tighten SOPs for weak workflow steps.
- Confirm reporting drives next actions.
- Adjust ownership or handoffs if needed.
- Recalculate cost assumptions using actual workload.
Phase 5: Scale decision (weeks 10-13)
- Decide model: software-led, service-led, or hybrid.
- Set scale gate using stability thresholds.
- Expand only after correction burden declines.
- Keep monthly governance review in place.
- Document quarter roadmap and expected checkpoints.
Weekly operator checklist
- Validate critical local profile fields.
- Review open issues by severity.
- Check SLA compliance for corrections.
- Confirm owner/due-date on every action item.
-
Capture lessons for next cycle adjustments.
Model Implementation and Stabilization Timeline
Common mistakes and fixes
| Mistake | Impact | Fix |
|---|---|---|
| Choosing by price only | Hidden correction costs grow | Use total operating cost model |
| No pilot before scaling | Wrong model fit discovered too late | Run controlled 90-day pilot |
| No ownership map | Tasks stall between teams | Define accountable owner and backup |
| Reporting without decisions | Optimization loop breaks | Require action-owner fields in reports |
| Scaling unstable workflows | Error rate grows with volume | Gate scale by stability thresholds |
FAQ
1) Is software always cheaper than service?
Not necessarily. Software can have lower direct fees but higher internal operating cost if ownership is weak.
2) When is service usually the better start?
When speed is needed and internal bandwidth cannot support consistent weekly execution.
3) What is the safest way to compare models?
Run a controlled pilot with the same baseline, KPI definitions, and review cadence.
4) Should teams avoid hybrid models?
No. Hybrid often works well when teams need both control and execution support.
5) Can either model guarantee ranking outcomes?
No. Reliable teams avoid fixed-date ranking guarantees and focus on process + directional trend signals.
6) When should we switch models?
Switch when workload, scale, or governance needs materially change and current model no longer fits.
Final takeaway
The software-vs-service decision is really a workflow design decision. Teams that choose based on fit, governance, and measurable execution quality usually outperform teams that choose on price or volume promises alone.


