Quick answer
A directory listing program scales when workflow quality is managed end to end: intake, qualification, publishing, verification, monitoring, and optimization. If any stage is weak, teams spend more time fixing errors than creating value.
The practical objective is not "submit everywhere." It is "run a predictable workflow where each cycle improves quality and decision clarity."
To make this operational, treat directory listing management as a stage-gated process with ownership, QA checkpoints, and monitoring rules.
sbb-itb-8e44301
Problem framing
Many listing teams execute submission but underinvest in monitoring. That creates a false completion signal: work looks done in the moment, but unresolved issues and data drift reduce long-term value.
The most common workflow gaps are structural:
- weak intake and inconsistent input data,
- no quality filter before directory selection,
- no controlled handoff between publishing and verification,
- no monitoring model after initial completion,
- reporting that captures activity but not decisions.
These gaps create recurring operational debt. Each new wave introduces fresh inconsistencies because old issues were never fully closed.
Where workflows usually fail
| Workflow stage | Typical failure | Why it happens | Consequence |
|---|---|---|---|
| Intake | Incomplete or ambiguous profile inputs | No mandatory field policy | Rework during publishing |
| Qualification | Low-fit directories included | No relevance score threshold | Low-signal output and cleanup burden |
| Submission | Uncontrolled bulk changes | No wave design | Hard-to-debug errors |
| Verification | Status not normalized | No clear verification checklist | Unreliable completion tracking |
| Monitoring | No recurring review cadence | Team assumes one-time completion | Quality decay over time |
| Optimization | No root-cause decision loop | Reporting lacks recommendations | Same issues repeat monthly |
A good workflow does not rely on heroic manual effort. It relies on clear stage rules.
Stage-gated workflow blueprint
| Stage | Entry criteria | Exit criteria | Owner role | Main artifacts |
|---|---|---|---|---|
| 1. Intake | Core business data received | Mandatory fields complete and validated | Operations lead | Intake form + canonical profile sheet |
| 2. Qualification | Intake complete | Directory set passes fit threshold | Growth/SEO owner | Approved directory shortlist |
| 3. Submission | Approved shortlist ready | Wave status recorded with timestamps | Execution owner | Submission log by wave |
| 4. Verification | Wave submitted | Acceptance/pending/issue statuses normalized | QA owner | Verification checklist + issue log |
| 5. Monitoring | Verification complete | Weekly health check completed | Ops or local owner | Monitoring dashboard |
| 6. Optimization | Monitoring signals available | Next-cycle actions assigned | Strategy owner | Decision memo + action plan |
This blueprint gives teams one key benefit: every cycle has explicit handoffs and accountability.
Workflow control matrix (what to enforce)
| Control area | Minimum standard | Why it matters |
|---|---|---|
| Input control | Canonical field schema and naming rules | Prevents data drift before publication |
| Wave control | Bounded submission batches with checkpoints | Limits blast radius of mistakes |
| Status control | Standard status taxonomy for every listing | Makes reporting and debugging reliable |
| Issue control | Severity scoring + SLA windows | Prioritizes customer-impacting fixes |
| Decision control | Required next-action owners and due dates | Converts reporting into execution |
Without these controls, teams default to reactive mode.
Decision framework: submit now or monitor first?
Use this rule before each new wave:
- If critical errors from prior wave are unresolved, monitor/fix first.
- If data consistency threshold is below target, monitor/fix first.
- If status taxonomy is incomplete, monitor/fix first.
- Submit new wave only when all three controls are stable.
This prevents scale from amplifying unresolved operational issues.
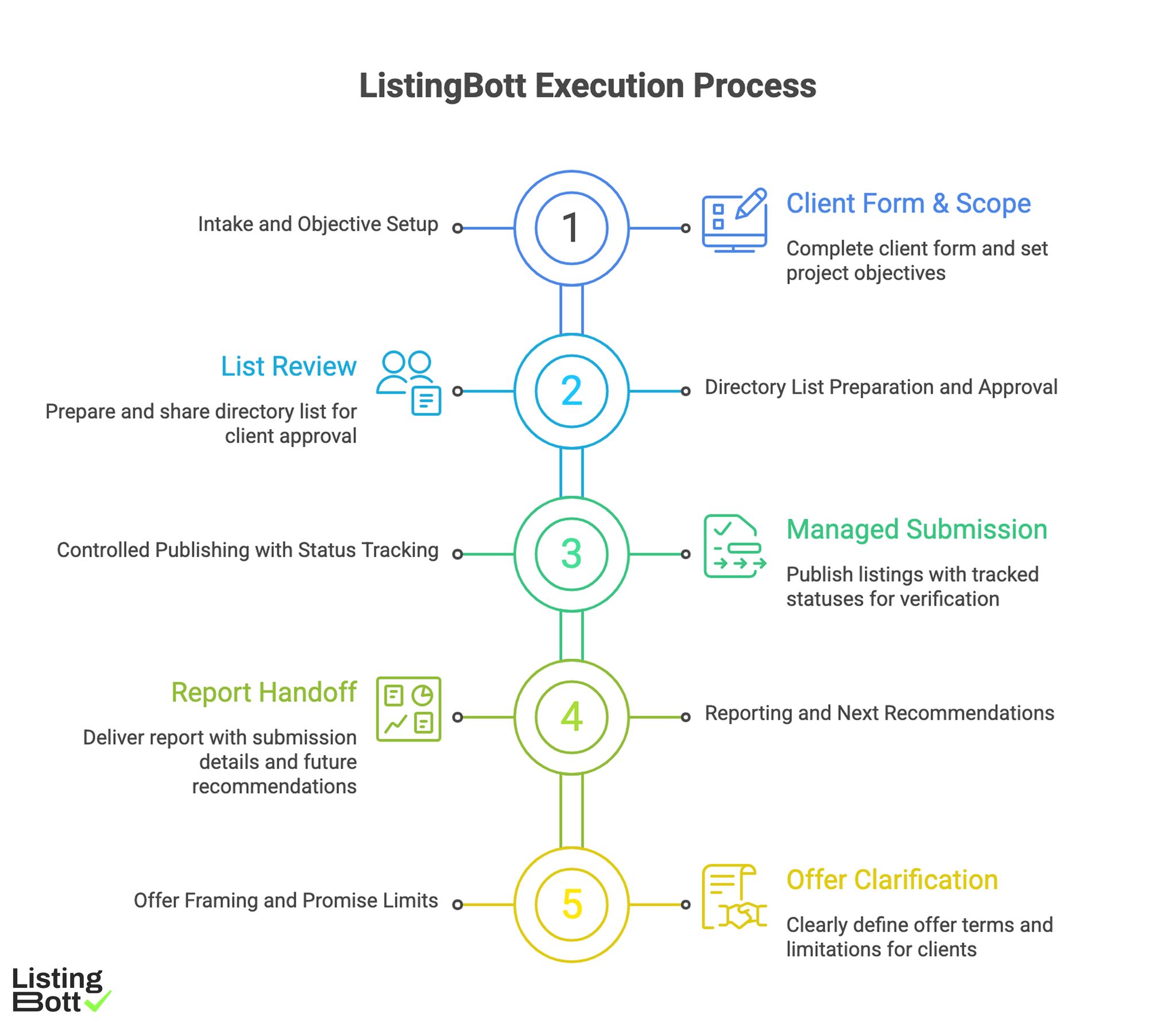
How ListingBott works
ListingBott runs listing execution as a structured process: client-form intake, directory-list approval, publishing, and report handoff. The model is designed to keep delivery and status communication clear.
1) Intake and objective setup
Execution starts with complete client-form data. Scope and objective are set before publishing begins, reducing ambiguity later.
2) Directory list preparation and approval
A proposed list is prepared and shared for approval before broad publish starts. This gate helps control relevance and quality.
3) Controlled publishing with status tracking
Publishing is managed with tracked statuses rather than unmanaged one-shot submissions. That supports cleaner verification and issue resolution.
4) Reporting and next recommendations
Each cycle closes with report-ready output: what was submitted, status by destination, pending items, and next recommendations.
5) Offer framing and promise limits
Current public offer framing includes one-time payment model, publication to 100+ directories (per current website language), no hidden extra fees (per current FAQ language), and refund possibility if process has not started.
ListingBott does not promise guaranteed ranking position, guaranteed traffic by a specific date, guaranteed indexing speed, or third-party platform outcomes.
For DR-goal work, DR growth to 15 is only in the qualified setup: starting DR below 15, explicit domain growth goal, and approved directory list.
Teams that need tighter execution can align this with a broader business directory submission process to keep stage transitions clean.
ListingBott Execution Process
Proof/results
The most reliable way to evaluate listing workflows is to measure stage performance, not just final submission count. Workflow metrics expose where reliability breaks before outcome signals degrade.
Workflow KPI stack
| KPI category | KPI examples | Diagnostic use | Review cadence |
|---|---|---|---|
| Intake quality | mandatory-field completion rate, invalid-input rate | Detects readiness issues before execution | Per wave start |
| Submission quality | wave completion rate, submission error rate | Detects execution control quality | Weekly during waves |
| Verification quality | status normalization rate, unresolved issue age | Detects closure reliability | Weekly |
| Monitoring quality | health-check completion rate, recurring issue ratio | Detects quality decay risk | Weekly |
| Optimization quality | recommendation implementation rate, next-cycle adoption | Detects learning loop strength | Monthly |
This structure helps teams isolate root causes quickly.
Monitoring model after initial publish
Post-publish monitoring should answer four questions every cycle:
- Which listings changed status since last review?
- Which issues are still open and why?
- Which errors are recurring?
- What should be adjusted in the next wave?
When monitoring skips one of these, teams lose decision precision.
Quality thresholds before scaling
| Threshold | Minimum healthy state |
|---|---|
| Intake readiness | High mandatory-field completeness |
| Submission control | Stable wave completion with low error volatility |
| Verification hygiene | Consistent status taxonomy across destinations |
| Monitoring discipline | Weekly review completion maintained |
| Optimization execution | Action items delivered by owner/date |
Scale should be gated by thresholds, not by pressure to increase volume.
Incident response playbook for listing workflows
| Incident type | Severity | Immediate action | Follow-up action |
|---|---|---|---|
| Critical field mismatch (phone/address/hours) | High | Fix across priority listings immediately | Add root-cause prevention rule |
| Duplicate profile conflict | High | Freeze related updates and reconcile records | Update dedupe protocol |
| Submission rejection cluster | Medium | Pause affected wave and inspect patterns | Adjust qualification filter |
| Reporting inconsistency | Medium | Reconcile status data and issue logs | Strengthen status taxonomy checks |
| Monitoring miss (skipped cycle) | Medium | Run catch-up health check | Add calendar + owner safeguard |
Incident playbooks are what keep workflow quality stable during growth.
Interpreting outcomes without overclaiming
Directory workflows can improve consistency, discoverability support, and decision quality over time. They should not be framed as guaranteed ranking outcomes by fixed dates. The strongest practice is to show directional progress linked to operational improvements.
This approach keeps expectations realistic and reduces preventable trust issues.
Implementation checklist
Use this plan to move from ad hoc submissions to a monitored, stage-gated workflow.
Phase 1: Workflow design (week 1)
- Define stage model and ownership map.
- Create canonical input schema.
- Set status taxonomy for all listing states.
- Define issue severity and SLA matrix.
- Build standardized report template.
Phase 2: Baseline and controls (weeks 2-3)
- Audit current listing state against canonical inputs.
- Map existing issues by stage (intake, submission, verification, monitoring).
- Set threshold rules for each stage exit.
- Start submission and issue logs with timestamps.
- Capture baseline workflow KPIs.
Phase 3: Controlled execution (weeks 4-6)
- Run bounded submission waves.
- Apply verification checklist at wave close.
- Normalize statuses and close urgent issues.
- Publish weekly monitoring summaries.
- Track owner action completion.
Phase 4: Monitoring hardening (weeks 7-9)
- Enforce weekly health-check cadence.
- Review recurring issue patterns.
- Tighten intake and qualification rules where failures repeat.
- Remove low-impact tasks from the critical path.
- Update stage thresholds based on data.
Phase 5: Optimization and scale (weeks 10-13)
- Expand only after thresholds are consistently met.
- Improve automation only for stable steps.
- Keep incident-response routines active.
- Compare cycle-over-cycle workflow KPI trends.
- Publish next-quarter workflow plan.
Weekly workflow checklist
- Validate critical field consistency.
- Review status changes since last check.
- Close high-severity issues first.
- Confirm owner/due-date for open actions.
-
Update monitoring and optimization notes.

Streamlining Listing Submissions: A 13-Week Journey
Common workflow mistakes and fixes
| Mistake | Why it hurts | Fix |
|---|---|---|
| Submission-first mindset | Monitoring debt accumulates | Gate new submissions by closure thresholds |
| Unclear status labels | Teams interpret progress differently | Standardize status taxonomy |
| No stage ownership | Handoffs fail and tasks stall | Assign explicit owner per stage |
| Monitoring done irregularly | Drift goes unnoticed | Lock weekly health-check cadence |
| Recommendations without owners | Same issues return | Require owner + due date for every action |
FAQ
1) What is the biggest mistake in directory listing workflows?
Treating submission as the finish line instead of running verification and monitoring as core stages.
2) How often should listing workflows be monitored?
Weekly for operational health and monthly for optimization decisions.
3) Should teams automate everything in listing management?
No. Automate stable, repeatable tasks; keep judgment-heavy steps under controlled review.
4) What metrics best predict workflow health?
Status normalization rate, unresolved issue age, wave completion reliability, and action-implementation rate.
5) Can a workflow guarantee ranking outcomes?
No. It can improve process quality and support outcomes, but fixed-date ranking guarantees are not reliable.
6) When should we scale listing volume?
Only when stage thresholds are stable and recurring issue patterns are controlled.
Final takeaway
Directory listing management is most effective as a monitored workflow, not a submission project. Teams that enforce stage gates, ownership, and monitoring discipline consistently produce better operational reliability and clearer strategic decisions.


